
In recent years, the field of generative AI has been growing at an impressive pace, and the competition among companies to develop the most powerful models has been fierce. These models are capable of generating a wide range of content, from images and text to even music. The potential for generative AI to revolutionize various industries, including art, entertainment, healthcare, and finance, is significant. A video was published yesterday (16th March 2023) on the AI Explained Youtube channel explaining how the disruptive AI landscape might already be disrupted.
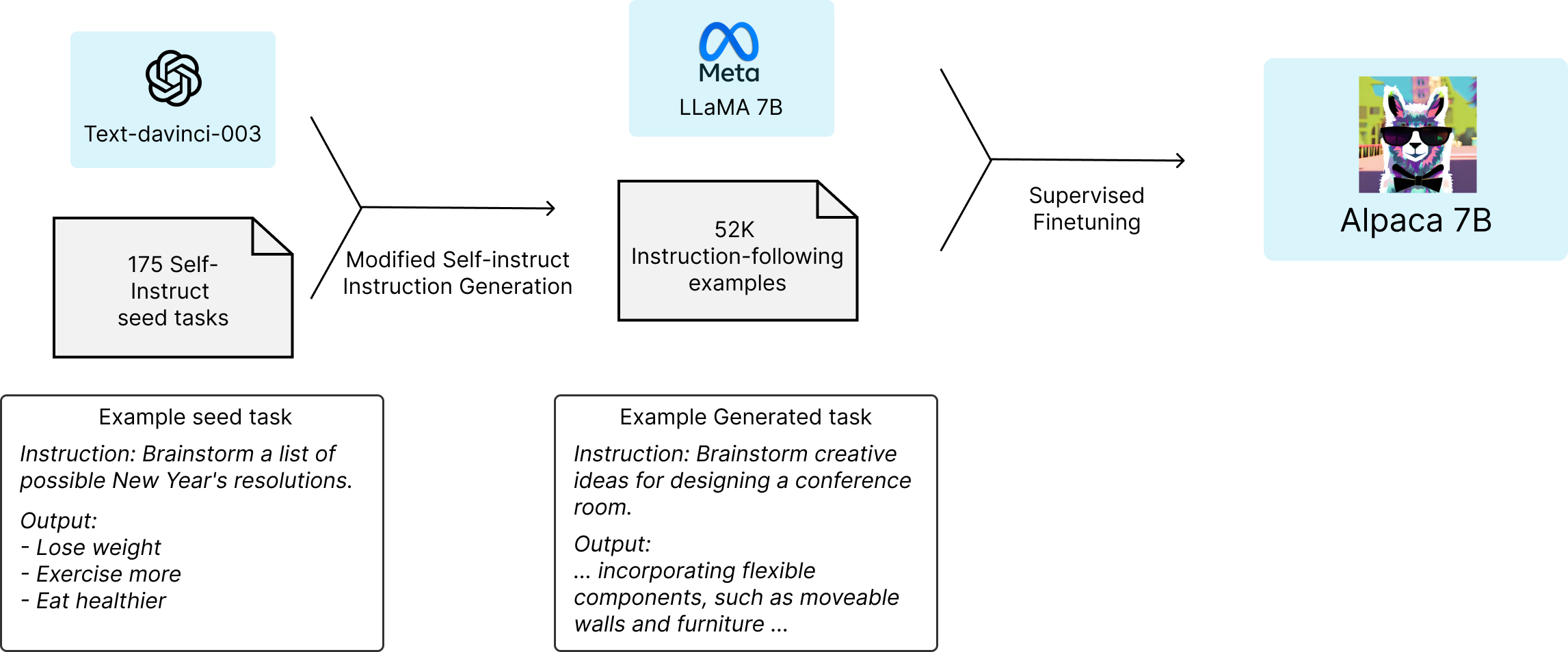
Recently, Stanford University released a language model called Alpaca, which could have a significant impact on the field of generative AI. According to reports, Alpaca behaves qualitatively similarly to OpenAI’s Text DaVinci 3, while being fairly easy, and cheap to reproduce at a cost of around $600 (using API calls to more mature models). Stanford’s breakthrough has reduced the potential cost of language modeling significantly. Just five weeks ago, Arc Investment Management predicted that the cost of a product like GPT 3 at $4.6 million in 2020 would take until 2030 to fall to around $30 effectively making a tool like GPT 3 a commodity. However, Stanford’s experience shows that 95% of this cost reduction has happened within five weeks of this prediction being published.
The Alpaca model was retrained from the Llama open-source model (Generative AI model open sourced by Facebook end of February 2023) through a technique called self-instruct, which significantly reduces the cost of language modeling as a result of almost completely removing human intervention in the model training requiring only a few human annotation compared with the initial effort required to build a model such as GPT3.5 from scratch. As per reports, Stanford used an open-source model, the weakest of the Llama models (LLaMa 7B), and trained it using results from prompts to GPT3.5. The end result was Alpaca. Stanford claims that its model performs comparably to GPT 3.5 which is amazing considering GPT3.5 uses 175 billion parameters where LLaMa 7B uses only 7 billion.
While this breakthrough is exciting, it also poses a risk to proprietary data. One reason why GPT3.5 and now GPT4 are so good is that they rest on proprietary data built by teams of experts during extensive periods of time, which was supposed to provide a competitive advantage. However, this advantage is now compromised as people can reuse this data to train new models. As a side note, OpenAI already identified this risk as they included this restriction in their terms of service:
2.C – Restrictions. You may not […] (iii) use output from the Services to develop models that compete with OpenAI; (iv) except as permitted through the API, use any automated or programmatic method to extract data or output from the Services, including scraping, web harvesting, or web data extraction;
Alpaca is a significant breakthrough in the field of generative AI, one that reduces the cost of language modeling and enables more people, including bad actors, to create new models with a significantly lower cost. It shows the power of self-instruct and pseudo-intelligence in models like Llama and GPT-3.5, allowing them to imitate and learn from other models. The Alpaca breakthrough is important, but it is not a surprise. We knew self-instructive models would be able to improve on themselves and on other models. However, we did not know how long it would take for this to happen or what the results would look like.

“SELF-INSTRUCT : a semi-automated process for instruction-tuning a pretrained LM using instructional signals from the model itself. The overall process is an iterative bootstrapping algorithm”
The implications of Alpaca’s release and recent revelations from Apple, Amazon, Britain (BritGPT), and Baidu make it particularly significant. Apple recently revealed that they are working on a large language model, and Amazon has been working on similar tech for a long time. Google also recently announced the PaLM API. As these companies and governments compete with each other, they also compete with outsiders who are trying to imitate their models.
The release of Stanford University’s Alpaca represents a significant precedent in the field of generative AI, reducing the cost of building AI models and enabling more people, including bad actors, to create new, cheap but effective models. This breakthrough shows the power of self-instruct and pseudo-intelligence in models like Llama and GPT-3.5, allowing them to imitate and learn from other models. As the field of generative AI continues to evolve, we can expect to see more breakthroughs and new challenges for companies to navigate as they strive to protect their proprietary technology.
As GPT4 released and more competitors are around the corner, we might see more and more copy models be built for cheap and used in the wild. And while the self-instruct framework was created for language generative AIs, the concept could possibly be applied to other kinds of generative AI models Interesting times ahead.
You can play with ALPACA pulling it from the Github repo here: https://github.com/tatsu-lab/stanford_alpaca
You can also try LLaMa from the github repo and try rebuilding a model by yourself: https://github.com/facebookresearch/llama